Mysql引擎
Mysql的Server层和引擎层
Server层负责建立连接、sql的语法解析、词法解析、执行优化、执行
此处延伸出一条查询sql语句是如何来进行的?
- 建立连接:有两种方式长链接和短连接,建立连接的话是需要进行TCP三次握手和四次挥手的,所以说如果采用短连接是会频繁的创建连接,是会消耗资源的,如果使用长连接,长时间不用的话,也是一种浪费
- 词法解析:主要判断一些关键词的词法是否有问题
- 语法解析:构建语法树
- 执行优化:判断当前查询语句适合使用什么索引,以及对sql进行优化
引擎层负责数据的存储和组织
- 引擎层是以row为单位给Server进行返回数据的
InnoDB和MyISAM存储引擎对比
| Feature | InnoDB | MyISAM |
|---|---|---|
| B+Tree indexes(B+树索引) | YES | YES |
| Locking granularity(锁粒度) | Row(基于MVCC实现) | Table |
| Transactions(事务) | YES | NO |
| Data caches(数据缓存) | YES | NO |
| Foregin key support(外键支持) | YES | NO |
InnoDB内存结构
InnoDB内存结构设计的思考
| 问题 | 描述 | InnoDB机制 |
|---|---|---|
| 异常宕机导致数据丢失 | 如果服务器异常宕机,Buffer Pool中的数据会丢失 |
Redo Log:用于记录事务日志,保证事务的持久性,异常宕机后,通过重做日志(Redo Log)重放已提交的事务,确保数据的一致性 |
| 读性能差 | 直接从磁盘中读取数据,会产生IO操作 | Buffer Pool:InnoDB通过在内存中缓存页(Page)减少磁盘IO。自适应哈希索引(Adaptive Hash Index,AHI):动态构建哈希索引,用于加速频繁访问的查询。 |
| 写性能差 | 直接写磁盘会产生磁盘IO操作 | 通过Buffer Pool、Change Buffer进行优化写性能 |
| 不支持事务 | 异常回滚 | Undo Log:记录事务的撤销操作,支持事务回滚和MVCC机制,保证数据的一致性和隔离性 |
内存结构
内存结构主要包含四大控件:Buffer Pool、Change Buffer、Log Buffer、Adaptive Hash Index
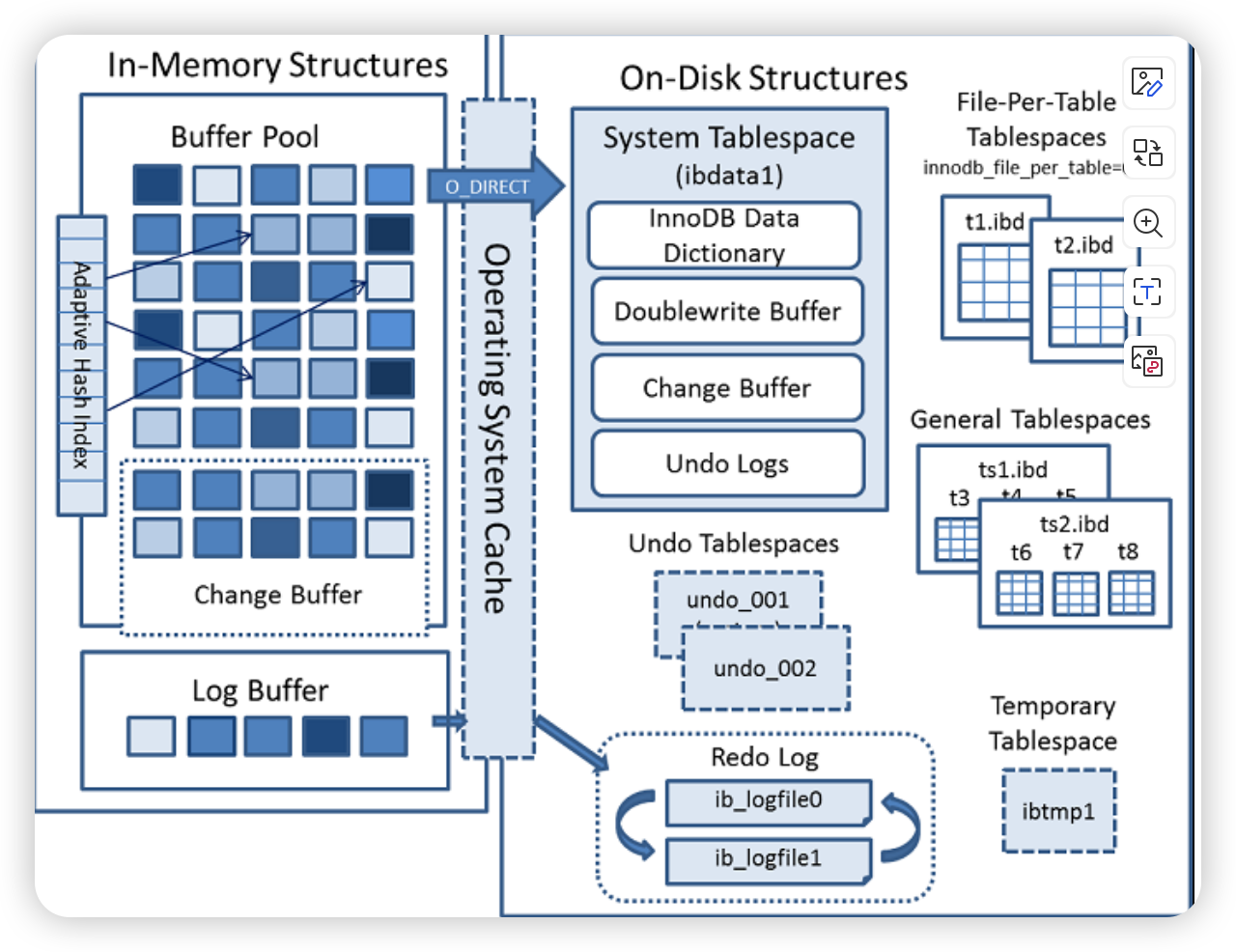
Buffer Pool
缓冲池,简称BP。BP是以页为存储单位的,内部通过链表来管理各个page页,在Innodb中访问记录直接从BP中获取,避免磁盘的I/O操作
BP通过链表管理page页,采用LRU算法根据访问的频次淘汰
改进型LRU算法:链表分为两部分,
new和old区,新加入的page放到5/8处(参数innodb_old_blocks_pct控制分界点,默认值为 37,相当于 5/8 处),如果一个页被频繁的访问,逐步的往new部分的前段,如果没有被访问过,逐步的往old区的后段挪,直到淘汰page页包含哪些?
- 脏页(dirty page):数据被修改
- 空闲页(free page):页被分配,但还未被使用的
- 干净页(clean page):数据没有被修改
脏页刷新到磁盘的时机?
Buffer Pool 的使用率达到一定阈值时:通过innodb_max_dirty_pages_pct控制,默认为75%
事务提交时,部分脏页可能刷新到磁盘
后台线程周期性刷新
页淘汰时
数据库关闭时
Change Buffer
写缓冲区。涉及到更新非唯一索引页的时候会采用Change Buffer
Change Buffer的主要目标是优化对非唯一的二级索引索引页更改操作,可以起到延迟写、减少磁盘I/O来提高性能
Log Buffer
Log Buffer,日志缓冲区,用来缓存redo log、undo log
什么时候会把日志刷新到磁盘中?
当缓冲区满了会进行刷新
innodb_flush_log_at_trx_commit参数控制日志刷新行为,默认为1
0:每隔1s进行刷新,这样实例宕机会丢失一秒中的事务
1:事务提交后,立刻写日志文件和刷盘,数据不丢失,但是会频繁IO操作
2:事务提交后,立刻写日志文件,每隔1秒钟进行刷盘操作
写日志文件(Log Buffer ==> Os Cache)
刷盘(OS Cache ==> 磁盘文件)
Adaptive Hash Index
自适应哈希索引,用于优化对Buffer Pool中数据页的查询。InnoDB存储引擎会监控对表索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立哈希索引,所以称之为自适应。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
针对仅仅是Buffer Pool中存在的B+树索引页
Innodb数据文件
Mysql一个表的数据和索引均存储在.ibd文件,ibd文件的分为段(Segement:数据段+索引段)、区(Extend:1MB、64个页)、页(Page:16K)、行(Row,最大65535字节),结构如下
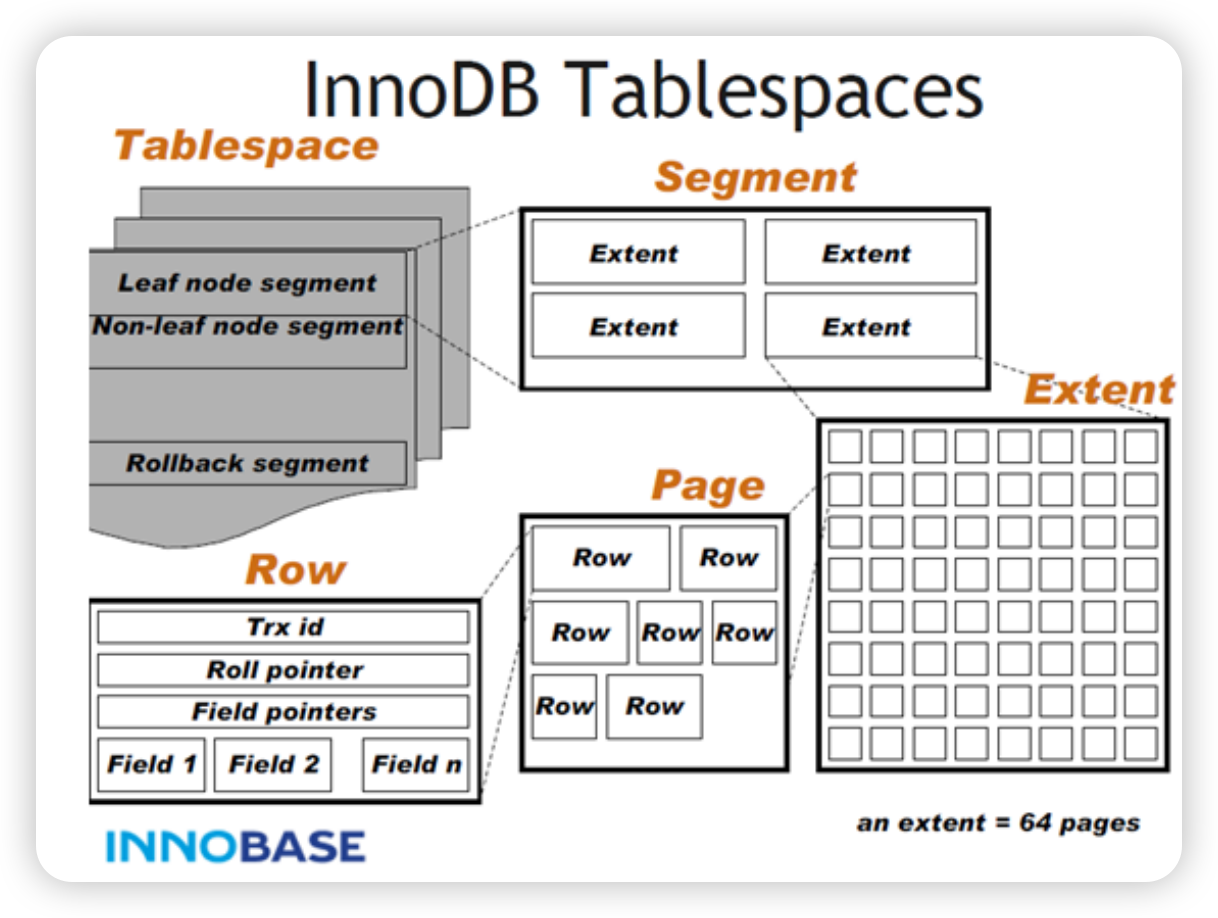
数据页中的数据是如何组织的?
- 数据页中的数据按照主键的顺序组成单链表,单链表的优点是插入、删除方便,查询不方便
- 每个数据页都会包含页目录,查找数据的时候,通过页目录进行二分查找来提高查询效率
为什么采用段、区、页的方式组织数据?
- 段(Segment):
- 数据段和索引段分开存储,逻辑清晰。
- 支持动态扩展,如为表增加索引时,会创建新的索引段。
- 区(Extent):
- 每个区由 64 个连续的页组成,是最小的空间分配单位。
- 按区分配有助于确保存储连续性,提高 I/O 性能,同时减少频繁分配小块空间的开销。
- 页(Page):
- 页是最小的存储单位(16KB),支持精细化管理和读写效率。
为什么
.ibd文件初始化后不是 2MB?- MySQL 8.0 中,初始化表后的
.ibd文件默认大小为 112KB,原因包括:- 按需分配策略:InnoDB 初始只分配少量页,用于存储表元数据和初始数据
- 逐步扩展机制:随着数据量增加,InnoDB 按需分配新的页和区,而不是一次性分配整个区(2MB)
- 避免浪费:初始表可能不需要完整的一个区,逐步分配能减少磁盘空间浪费
- 段(Segment):
示例
执行语句update user set name = '11' where name = '22'
通用步骤
- 开始事务
- 分配事务Id、创建Read View供回滚使用
- 执行update
- 无索引:根据聚簇索引进行全表扫描
- 有索引:根据索引定位到数据行(唯一索引可以直接定位到行、非唯一索引可能要经过多次查找)
- 若数据不存在Buffer Pool中,需要涉及到磁盘I/O
- 写undo log
- 在修改数据前,生成undo log记录旧值
- 写undo log到log buffer中,通过redo log保证持久化
- 更新数据页
- 修改数据,并标记为脏页
- 涉及到索引
- 非唯一索引:变更记录到change buffer
- 唯一索引:立即更新索引页
- 写redo log
- 记录数据页和undo log的修改到log buffer
情况一:name列上没有索引
流程:
- 通过聚簇索引进行全表扫描
- 逐行加载数据页到buffer pool中,并标记为脏页
情况二:name列上有非唯一索引
流程:
- 通过二级索引定位到所有name=’22’
- 通过聚簇索引修改数据页
- 二级索引更新延迟:操作均缓存在change buffer中,避免立即加载所有索引页
- 后续读取改索引页时,合并change buffer中的修改
情况三:name列上有唯一索引
流程:
- 通过唯一索引定位name=’22’
- 通过聚簇索引修改数据页
- 更新主键索引和唯一索引的数据页,标记为脏页
提交事务
redo log和undo log的两阶段提交
Prepareing阶段:设置redo log为prepare
Wtire Binlog阶段:生成并刷盘binlog
Commit阶段:将redo标记为commit并刷盘
后台刷新脏页
友情链接: